经过 2 个 Python 项目的洗礼(加一起 2k 行代码了), 现在再回过头看以前的文章, 实在看不下去, 所以现在有空就重制一下该系列
环境:python3.11
pip install beautifulsoup4 httpx
httpx 的进阶用法 异步/控制并发数/多线程/线程池 的爬虫方法我们放在下一篇文章讲解, 本篇文章主要讲基本使用
httpx 基本用法
# 是否启用代理
proxy_status = True
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/535.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/535.36",
"referer": "https://movie.douban.com/"
}
# cookies
cookies = {
"token": "123"
}
# 代理
proxies = {
'http://': 'http://127.0.0.1:7778',
'https://': 'http://127.0.0.1:7778',
}
# 判断是否代理
if not proxy_status:
proxies = {}
with httpx.Client(headers=headers, proxies=proxies, cookies=cookies) as client:
print(client.get("https://www.baidu.com/", timeout=10).status_code)
豆瓣
我们先来看看一个简单的例子,请求页面用 httpx,页面的数据分析用 bs4
- 获取内容我建议是使用:
select_one()、select()- 里面通过 CSS 选择器 获取对象,这会方便很多。
- 下面我们来举一个豆瓣 TOP250 的例子
import time
import httpx
from bs4 import BeautifulSoup
import atexit
start_url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/535.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/535.36",
"referer": "https://movie.douban.com/"
}
start = time.time()
atexit.register(lambda: print('用时(秒):', time.time() - start))
def get_data(page_id):
with httpx.Client(headers=headers) as client:
# 获取网页信息
r = client.get(
f'https://movie.douban.com/top250?start={page_id}&filter=')
# 解析页面信息
soup = BeautifulSoup(r, 'html.parser')
data = []
# 获取整个页面的信息
for i in soup.select('ol.grid_view .item'):
_item = {'id': None, 'name': None}
# 序号
_item['id'] = i.select_one('.pic > em').get_text()
# 名称
_item['name'] = i.select_one('.info span.title').get_text()
data.append(_item)
return data
def main():
finalData = []
# 遍历
for i in range(0, 250, 25):
finalData.append(get_data(i))
return finalData
data = main()
print(data)
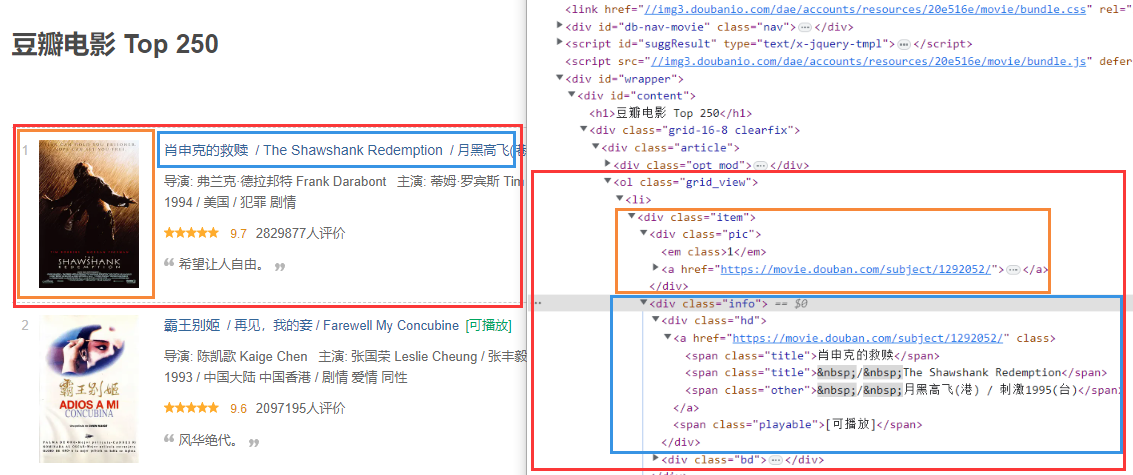
解析
- 相同颜色的框,代表他对应的内容。
- 29 行,我先用
for选择中了这 25 个列表元素 - 然后通过遍历分别获取他们的排序和名称,最后返回结果。
- 用时:3.5s
bs4
pip install beautifulsoup4
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
- beautifulsoup4 获取目标值一般分为两个步骤
- 第一步: 选中目标元素 (
select) - 第二步: 获取元素中的具体值(比如文本, 属性) 接下来我们来看下具体操作
- 第一步: 选中目标元素 (
select()
select(): 返回数组- 找不到返回空数组
[]
- 找不到返回空数组
select_one(): 返回一个- 找不到返回
None
- 找不到返回
r = """
<div id="content">
<h1>Hello World</h1>
<p class="item">
<a href="https://www.douban.com">
<img src="./douban.jpg" />
</a>
</p>
</div>
"""
soup = BeautifulSoup(r, 'html.parser')
# 找不到返回 []
if not soup.select("#content123"):
print("Not Found")
else:
print(soup.select("#content")[0]) # 返回的是数组
# 找不到返回 None
if soup.select_one("#content123") is None:
print("Not Found")
else:
print(soup.select_one("#content"))
这样我们就已经选中元素了, 接下来我们来看看如何获取具体的属性/文本
获取属性值
提醒下, 我只推荐使用
get()来获取属性, 我知道还有一种是soup.p.a的方式, 但是这种方式的原理是soup.find()容易误判并且过于长了
获取 a 标签的 href 地址
get()- 找不到返回
None
- 找不到返回
# <a href="https://www.douban.com">
data = soup.select_one("a")
if data is None:
print("Not Found")
else:
href = data.get("href")
# 不是 None 时输出
if href is not None:
print(href)
获取文本
如何获取 h1 标签文本呢?
getText()getText('\r\n', '<br/>')- 将
<br/>替换成\r\n
- 将
data = soup.select_one("p")
if data is None:
print("Not Found")
else:
h1 = data.getText()
# 不是 None 时输出
if h1 is not None:
print(h1)
正则
补充下正则的用法, 在格式化数据时非常有用
.compile(pattern, flags=0): 编译正则表达式- 使用 compile 函数进行预编译,可以提升程序的执行性能
.match(pattern, str, flags=0): 成功就返回匹配的对象, 失败则返回 None- 用来截取文本
- 使用
group()或者groups()获取结果, 不存在会返回None
下面这个方法我们用于 获取时间, 我使用了 () 原子组因此可以直接获取
r = r"该文章是由 ABC 用户于 2024-01-01 12:30 发表"
# 找不到返回 None
data = re.compile('.*(\d{4}-\d{1,2}-\d{1,2}.*\d{1,2}:\d{1,2}).*').match(r)
if data is None:
print("不存在")
else:
# group: 2024-01-01 12:30
print(data.group(1))
# 数组也可以, 结果是一样的
print(data[1])
# groups: ('2024-01-01 12:30',)
print(data.groups())
- 接下来介绍下
flags=0怎么写, 一般不用管re.I: 区分大小写re.S: 匹配任意字符, 包括换行re.M: 多行模式re.ASCII: 使得特殊字符类\w,\W,\b,\B,\d,\D,\s,\S只匹配 ASCII 字符。re.U: 使得特殊字符类\w,\W,\b,\B,\d,\D,\s,\S匹配 Unicode 字符。re.X: 忽略正则表达式中的空白和注释。
最后
bs4 其实就这么点知识, 只要你会通过 css 样式去选择元素就不难, 爬虫主要难点不在这, 在线程处理, 以及异常处理, 后面会说
基本一个合格的爬虫脚本, 都是要经过好几个版本的迭代的, 因为你无法预测所有未知的情况.