经过 2 个 Python 项目的洗礼(加一起 2k 行代码了), 现在再回过头看以前的文章, 实在看不下去, 所以现在有空就重制一下该系列
环境:python3.11
pip install sqlite3
pip install loguru
多线程方案对比
asyncio- I/O 密集型
- 涉及到网络、内存访问、磁盘 I/O 等的任务
- 例如网络请求、文件读写、数据库查询
- I/O 密集型
concurrent.futures- cpu 密集型
- 例如大规模数据处理、科学计算、图像处理等
- 比如求素数, 求平方值
httpx 异步案例
先来运行下这个小案例, 然后我们再看看原理和使用方法
httpx.Limitsmax_connections: 限制同一时间请求数量, 默认 100keepalive_expiry: 空闲时保持活动连接的时间限制, 默认 5max_keepalive_connections: 允许的保持活动连接数, 默认 20
asyncio.Semaphore(2)- 限制并发数
import atexit
import httpx
import asyncio
import time
import concurrent.futures
start = time.time()
atexit.register(lambda: print('用时(秒):', time.time() - start))
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/535.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/535.36",
"referer": "https://movie.douban.com/"
}
async def fetch_url(semaphore, client, url):
async with semaphore:
print(url)
response = await client.get(url)
# 使用 asyncio.sleep() 来模拟异步延迟
# await asyncio.sleep(1)
print(url, "yes")
return True
async def main():
# max_connections: 限制同一时间请求数量
# keepalive_expiry: 空闲保持活动连接的时间限制
# max_keepalive_connections: 允许的保持活动连接数
limits = httpx.Limits(max_connections=100, keepalive_expiry=5, max_keepalive_connections=20)
# 限制并发数
semaphore = asyncio.Semaphore(2)
urls = [f'https://movie.douban.com/top250?start={i}&filter=' for i in range(0, 250, 25)]
async with httpx.AsyncClient(limits=limits) as client:
task_list = []
for url in urls:
req = fetch_url(semaphore, client, url)
task = asyncio.create_task(req)
task_list.append(task)
# 等待获取返回结果
print(await asyncio.gather(*task_list))
# 开始
asyncio.run(main())
httpx 异步线程池的实验
AsyncClient: 异步 httpx 的原理是新建一个线程池, 先把请求添加进池子里, 再通过 max_connections 限制同一时间并发请求数量
我们来测试下, 我们再上面代码的基础上修改
limits = httpx.Limits(max_connections=1, keepalive_expiry=0, max_keepalive_connections=0)
# 解除并发限制
semaphore = asyncio.Semaphore(99)
实验结果: 我们会发现后面的结果是一个个输出的, 这就说明 max_connections=1 是有效的. (keepalive_expiry与max_keepalive_connections必须设置为 0, 否则会导致输出太快, 不好判断)
asyncio.Semaphore 作用
假如我不希望按照请求来并发, 我希望每 2 个方法执行完毕, 才执行下一个.
那你就可以使用 asyncio.Semaphore
semaphore = asyncio.Semaphore(2)
concurrent.futures 线程池
import concurrent.futures
# 定义一个 CPU 密集型任务
def compute_square(n):
return n * n
# 使用 ThreadPoolExecutor 创建线程池
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# 提交多个任务到线程池
results = [executor.submit(compute_square, i) for i in range(10)]
# 每次任务完成时调用
for future in concurrent.futures.as_completed(results):
print(f"Result: {future.result()}")
# 等待全部执行完成后返回结果
data = [future.result() for future in futures if future.result() is not None]
print(data)
网络请求错误(装饰器)
假如我们在多线程请求的时候, 发生了网络请求错误时, 该如何回调重新调用呢?
下面代码我使用了装饰器, 捕获 httpx.ConnectError 异常, 等待 3 秒后重新重试
def custom_exception_handler(exception_type, max_retries=3):
def decorator(func):
async def wrapper(*args, **kwargs):
retries = 0
last_exception = None
while retries < max_retries:
try:
return await func(*args, **kwargs)
except exception_type as e:
last_exception = e
print(f"Caught {exception_type.__name__} exception (retry {retries + 1}/{max_retries}): {e}")
retries += 1
# 等待3秒后重试
await asyncio.sleep(3)
print(f"Failed after {max_retries} retries: {last_exception}")
return None
return wrapper
return decorator
@custom_exception_handler(httpx.ConnectError, max_retries=3)
async def fetch_url(semaphore, client, url):
async with semaphore:
print(url)
# 模拟出现了网络问题
if url == 'https://movie.douban.com/top250?start=225&filter=':
url = 'https://movie.123douban.com/top250?start=225&filter='
response = await client.get(url)
print(url, "yes")
return True
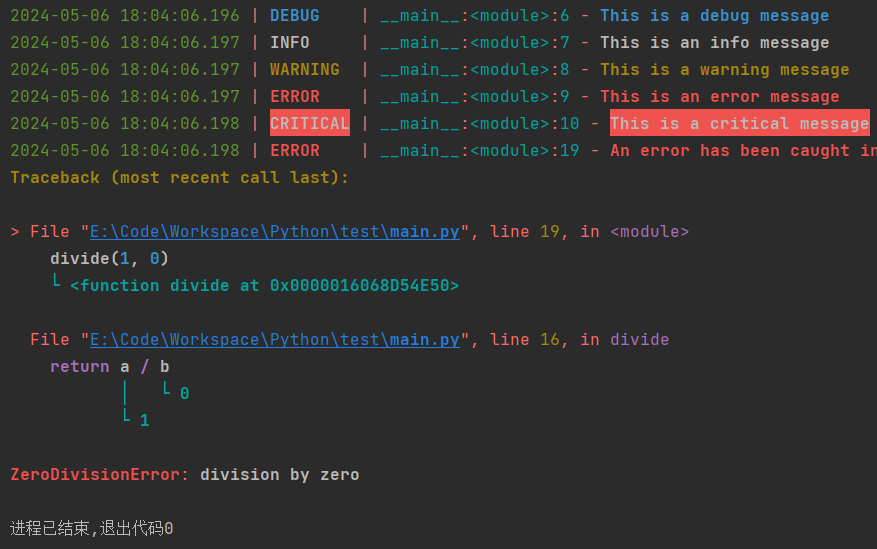
日志 loguru
- 功能和上面的差不多
- 当文件大于 10MB 时,轮换
@logger.catch:装饰器用于监听函数内的报错- ⚠️ 这是一个异常捕获机制
from loguru import logger
from datetime import datetime
logger.add(f'./log/{datetime.today().date()}.log', rotation='10 MB')
logger.debug("This is a debug message")
logger.info("This is an info message")
logger.warning("This is a warning message")
logger.error("This is an error message")
logger.critical("This is a critical message")
# 装饰器
@logger.catch
def divide(a, b):
return a / b
divide(1, 0)
sqlite3
import sqlite3
# 连接数据库
conn = sqlite3.connect('data.db')
c = conn.cursor()
c.execute('''CREATE TABLE stocks
(date text, trans text, symbol text, qty real, price real)''')
c.execute("INSERT INTO stocks VALUES ('2022-01-05', 'BUY', 'GOOG', 100, 35.14)")
c.execute("INSERT INTO stocks(date) VALUES (?)", ('John',))
# 提交
conn.commit()
# 关闭
conn.close()